
Summary
The data scientists at Unified Patents trained the LTE and 5G RAN Objective PAtent Landscaping analytics (OPAL), using large sets of expert reviewed RAN infrastructure patents to objectively score the statistical essentiality of any granted patent publication worldwide covering LTE or 5G functionality. A short summary of the methodology follows:
- Universe of Patents Subject to Analysis - 4.5 M applications and granted patents relevant to LTE and 5G RAN.
- Patents Evaluated Manually by Experts - 6.6 K families self-declared to ETSI for 3GPP evaluated manually by the 3GPP experts at Concur IP, who performed the analysis for the 2015 TCL vs Ericsson case in the US and the 2017 Unwired Planet vs Huawei case in the UK.
- AI Training - ML Algorithms were trained using FastText vectorization of the title, abstract, and claims of each patent to score their statistical essentiality to the LTE and 5G RANs based on semantic similarity.
- ML Performance - Training complied with good ML training practices and the results earned high F-1 scores of 0.999 for 5G and 0.998 for LTE.
Basis for Using Machine Learning to Predict Essentiality
The question of who owns LTE and 5G radio access network (RAN) standard-essential patents is an issue that many institutions and companies are grappling with as these important technologies are deployed. Many have claimed through declarations that they own LTE and 5G RAN essential patents, but there is currently no economically sensible way to evaluate these claims. At least when companies self-declare their LTE and 5G RAN patents, they also generally agree to license them on a fair, reasonable, and non-discriminatory (FRAND) basis, often limiting their use for securing injunctions and disproportionately high royalties. Unfortunately, other standards teach that there are many potentially essential patents that are never declared and that are not encumbered by any FRAND obligations. Unified Patents' LTE and 5G RAN landscapes, called LTE RAN OPAL and 5G RAN OPAL, not only identify self-declared LTE and 5G RAN patents but also these undeclared and FRAND-unencumbered patents.
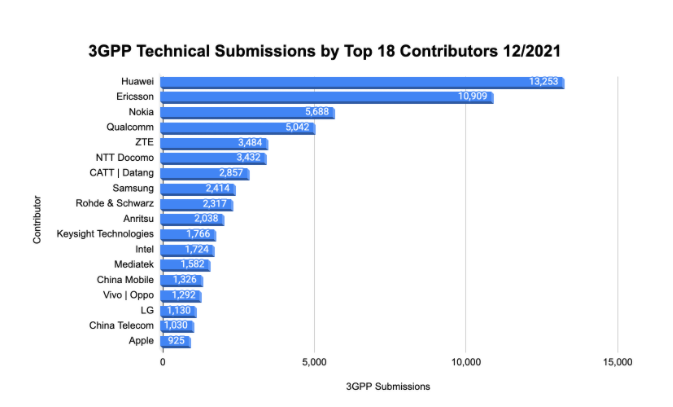
According to OPEN, Unified Patents’ 3GPP standards submissions database, over 56,000 LTE and 5G RAN technical contributions have been submitted. Close to 84.5% of those submissions included participation from at least one of the top 18 contributors shown above and 46.4% of those submissions were approved or agreed on.
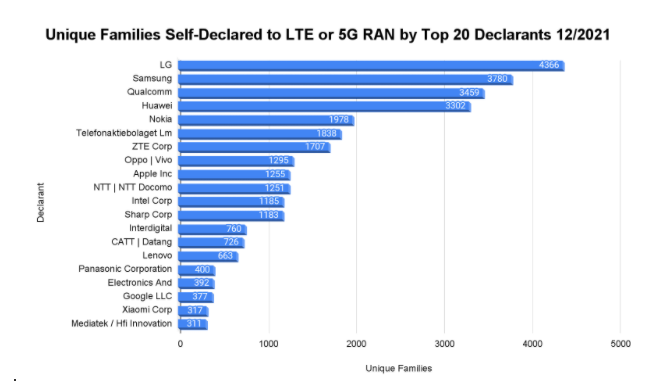
A large number of companies and institutions have self-declared through ETSI their patents and patent applications to be essential to the LTE and 5G RAN specifications. As of December 2021, over 250 K patents and applications have been self-declared after removing any duplicates. This number represents over 32 K families. A little over 23 K families were self-declared to 5G RAN and close to 17 K families were self-declared to LTE RAN. Of the 32 K families uniquely self-declared to the LTE RAN or 5G RAN, close to 95% are active in that they have an active pending application or active grant. Of the 250 K applications and grants uniquely self-declared to LTE RAN or 5G RAN, about 25% have been granted and are still active.
Due to the large number of patents and applications self-declared to LTE RAN and 5G RAN and the large number of technical submissions made to these standards, it is prohibitively expensive and time consuming to manually review and claim chart each patent and application that potentially could be essential to the LTE RAN or 5G RAN. An independent manual review and claim charting of each publication can cost more than $5,000 K and take as much as 4-10 hours. The costs to analyze a portfolio of just 100 self-declared essential publications could amount to $500,000 and take 10 work weeks for a single patent attorney.
Unfortunately, even spending the money and time on manual reviews does not guarantee a true view of essentiality or the size of the essential landscape. Reviewers do make mistakes or may even be biased. Regardless of the qualifications of the reviewers and the quality of their analysis, the results will invariably be disputed. For example, The percentage of self-declared patents estimated by courts and experts to be actually essential ranges from 50% to lower than 20%. In 2005, Goodman and Myers found 21% of self-declared patents in 3G were essential. In 2010, Fairfield Resources estimated 50% of self-declared patents in LTE were essential. In the remanded US TCL vs Ericsson case, the court’s calculation resulted in about 40% of all 2G, 3G, and LTE self-declared patents being essential. Finally, in the UK Unwired Planet vs Huawei case, the court used 16.6% to calculate the number of essential LTE patents from all self-declared ones.
Recognizing this, Unified Patents turned to ML-based analytics to predict the essentiality of tens of thousands of patents to the LTE and 5G RANs. The criteria set for for the analytics were unwavering objectiveness, transparency, cost-efficiency, and consistency and sufficient reliability. Further, to improve their reliability, the analytics will be developed year over year.
Sampling, Manual Reviews, and Training Sets
Unified Patents trained several ML algorithms, one each for LTE RAN and 5G NR RAN, to predict essentiality based on the vectorized semantics of thousands of patents manually reviewed by independent experts to be essential.
To collect its positive and negative training cases, Unified Patents contracted with Concur IP, the Indian IP technical services consultancy that reviewed the GSM, WCDMA, and LTE SEP landscapes for TCL in its FRAND licensing case against Ericsson decided in 2017 (appealed and remanded). Concur IP’s technical experts were also used by Huawei to review the LTE SEP landscape in its FRAND dispute in the UK against Unwired Planet decided in 2017 (upheld on appeal). The accuracy of Concur IP’s reviews of the LTE landscape in the TCL case was found to be around 90% when independently validated by a telecommunications professor at a renowned US university.
Concur IP created a list of patents to be manually reviewed by randomly selecting 6.6 K English language patent families with infrastructure claims declared to the LTE and 5G RAN standards. The random selection was conducted to ensure that the distribution of families was proportional to each declarant’s share of the overall number of families declared to ETSI specifically to the LTE and 5G NR RAN standards.
Concur IP’s independent technical experts then manually reviewed the claims of each family member without knowledge of the purpose of the review until evidence was identified in the relevant technical specifications for each element of a claim for essentiality. The priority of review was for independent claims followed by dependent claims and geographically in the order of US, EP, CN, JP, SK, and WO publications. Once the essentiality of a family member was evidenced, the entire family was deemed for the purposes of the training to be essential. If no claim was found to be essential, then the entire family was deemed not to be essential. The reviews resulted in four sets of families: two Positive Essentiality Sets of 9.9 K publications for LTE RAN and 7.6 K publications for 5G RAN and two Negative Essentiality Sets of 48.6 K publications for LTE RAN and 56.3 K publications for 5G RAN. The Negative Essentiality Sets were augmented with clearly unrelated and non-3GPP publications.
|
Training Set Composition |
LTE RAN Manually Reviewed |
5G NR RAN Manually Reviewed |
LTE RAN Family Expanded |
5G NR RAN Family Expanded |
|
Essential |
449 |
526 |
9,889 |
7,562 |
|
Non-Essential |
1,938 |
5,257 |
48,557 |
56,318 |
|
Total |
2,387 |
5,783 |
58,446 |
63,880 |
Essentiality ML Training
Unified Patents’ team of data scientists and patent attorneys used the Positive Essentiality Sets and Negative Essentiality Sets to train separate ML algorithms for LTE RAN and 5G NR RAN to predict potential essentiality based on semantic similarity. The training was conducted using good ML training practices.
The title, abstract, and claims of each patent in the Essentiality Sets were vectorized using the FastText (word2vec) text vectors and top 1,000 CPC embeddings. Initially, 400 dimensions were used to distinguish the vectors but this was reduced to 40 to reduce the risk of overfitting. The training model used was an ensemble of XGBoost and shallow extra-randomized forest from Scikit-Learn. The class weights of the Positive Essentiality Sets and Negative Essentiality Sets were also balanced.
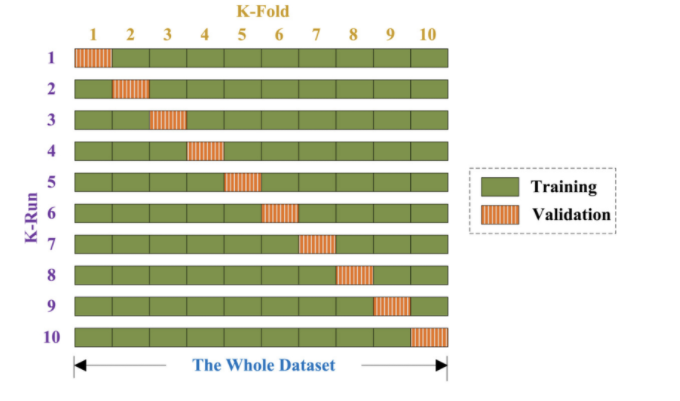
In training the ML algorithms, a stratified K-fold cross-validation process was deployed. This stratified resampling was used to correct any optimistic errors resulting from imbalanced data sets as well as to preserve the proportionality among the cross-validation testing and training sets.
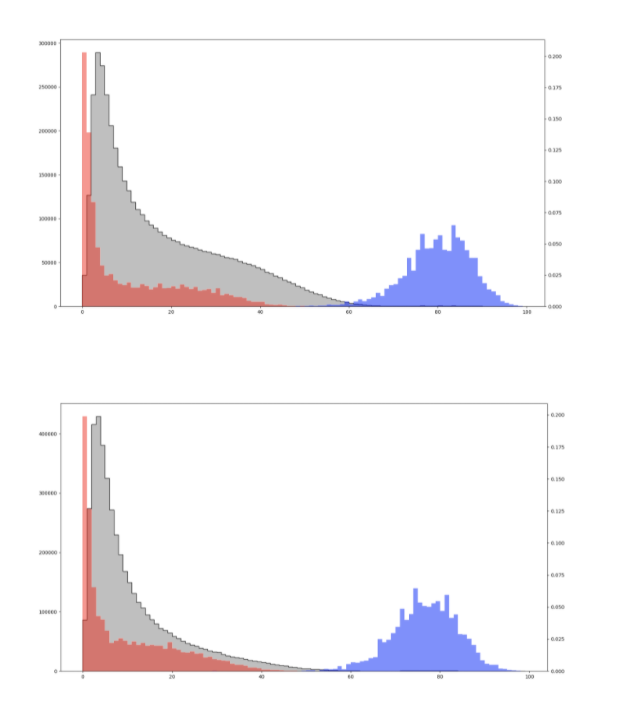
Unified Patents generated a relevant universe of 4.5 M vectorized publications that were (i) declared to 3GPP, (ii) contained one of the top 1,000 CPCs used in LTE and 5G RAN declared patents, or (iii) referenced 3GPP. Note that the relevant universe includes a lot more publications than just publications declared to 3GPP. Excluded from this universe were clearly unrelated publications such as those covering pharmaceuticals and materials engineering. The ML algorithms were then tasked with predicting the semantic similarity of each vectorized publication in the relevant universe with their trained view of what constitutes an essential patent. The resulting scoring for each publication was on a scale of 0-100, with 100 being the highest with respect to semantic similarity. The distributions of the scores for the positive (blue) and negative (red) LTE Essentiality Sets and positive (blue) and negative (red) 5G Essentiality Sets are shown below against the total scored population (grey).
OPAL Performance
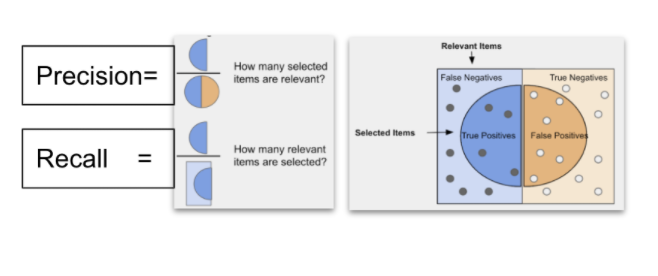
The performance of the ML algorithms resulting from the training earned very high F-1 scores of 0.999 for 5G NR RAN and .998 for LTE RAN. The F-1 scoring captures the harmonic mean of precision and recall where precision equals the number of true positives divided by the number of all positive results and recall equals the number of true positives divided by the number of all samples that should have been identified as positive.
Comments
0 comments
Please sign in to leave a comment.