
OPAL
Objective PAtent Landscape (OPAL)
LTE (3GPP Zone)
Patent Population
General Database – 90,000,000 patents from 98 countries
SEP (Self-Declared Standard Essential Patents) Database – 250,000 patents from 69 countries, 35 SSOs (Standard Setting Organizations) and multiple patent pools
Standards
Technical proposals, specification drafts, meeting minutes, attendance lists and working group participation are all collected and indexed by:
- Parsing all available electronic documents of the standard body
- Normalizing company and individual names
- Matching of standard document IDs to contributions
We host documents (such as technical proposals, meeting summaries, test results, etc.) from select standard-setting bodies on our online portal.
Training Set
To train a machine learning algorithm, representative sets of true positives (likely essential) and true negatives (likely not essential) are required.
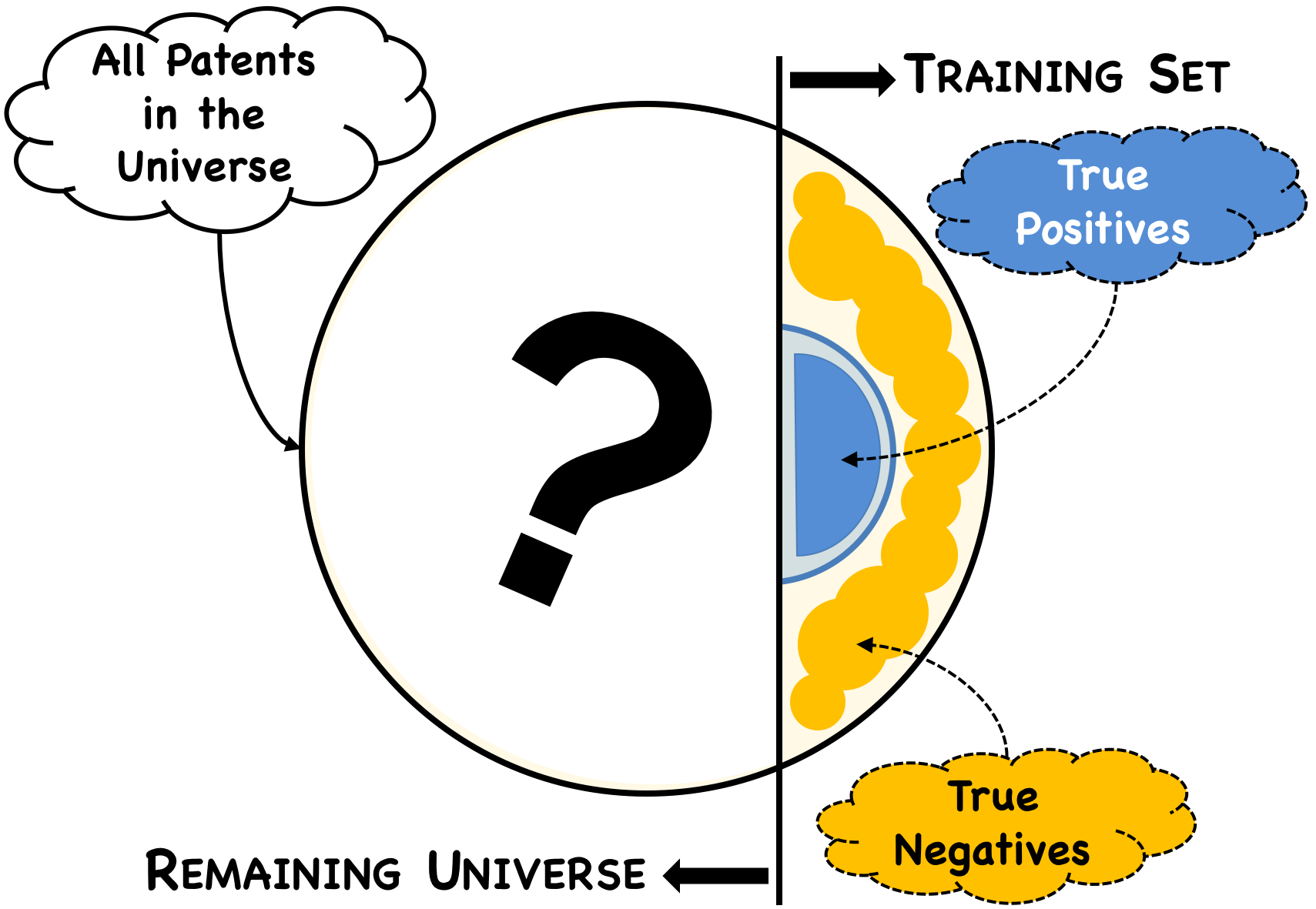
For this landscape, a portion of our training data was sourced from TCL Comm. Technology Holdings Ltd. v. Telefonaktiebolaget LM Ericsson, et al., No. 8:14-cv-00341 (C.D. Cal. 2014), a case involving FRAND royalties and LTE technology. Among other things, the court in this litigation was tasked with resolving the question of apportionment and deciding between the defendant's declaration-counting approach versus the plaintiff's competing patent-counting approach. For other aspects of this case, there are many resources available on the Internet for the reader (e.g. here, here, here, here).
Regarding the question of apportionment, the TCL plaintiff proffered an estimate for the total number of actually essential LTE patent families to serve as the "denominator" in their patent-counting approach. To support their estimate, the plaintiff introduced a patent landscape into court as an exhibit as well as declarations from experts involved in its creation (see here and here). The court ultimately approved of the landscape in spite of multiple challenges (see pages 27 through 32 here).
After carefully reviewing the methodology as well as the court's findings, we decided to incorporate the TCL landscape into our training set. Specifically, we adopted the 593 patent families marked essential to LTE as our set of true positives. These essential families amount to 13,920 individual patents worldwide. The remaining non-LTE patent families from the landscape were included in our set of true negatives. We further bolstered this set by including ETSI patents that were declared to non-LTE standards (such as 2G and 3G) and that could have been declared to LTE by the declaring party but were not for whatever reason. In total, our negatives consist of 95,894 individual patents worldwide.
Landscape Universe
Running a machine learning algorithm on all ~90M patents in the entire patent database is computationally expensive in terms of both costs and time. Thus, using multiple techniques, we narrowed the universe to only those patents that are relevant to (or at least tangential to) LTE technology.
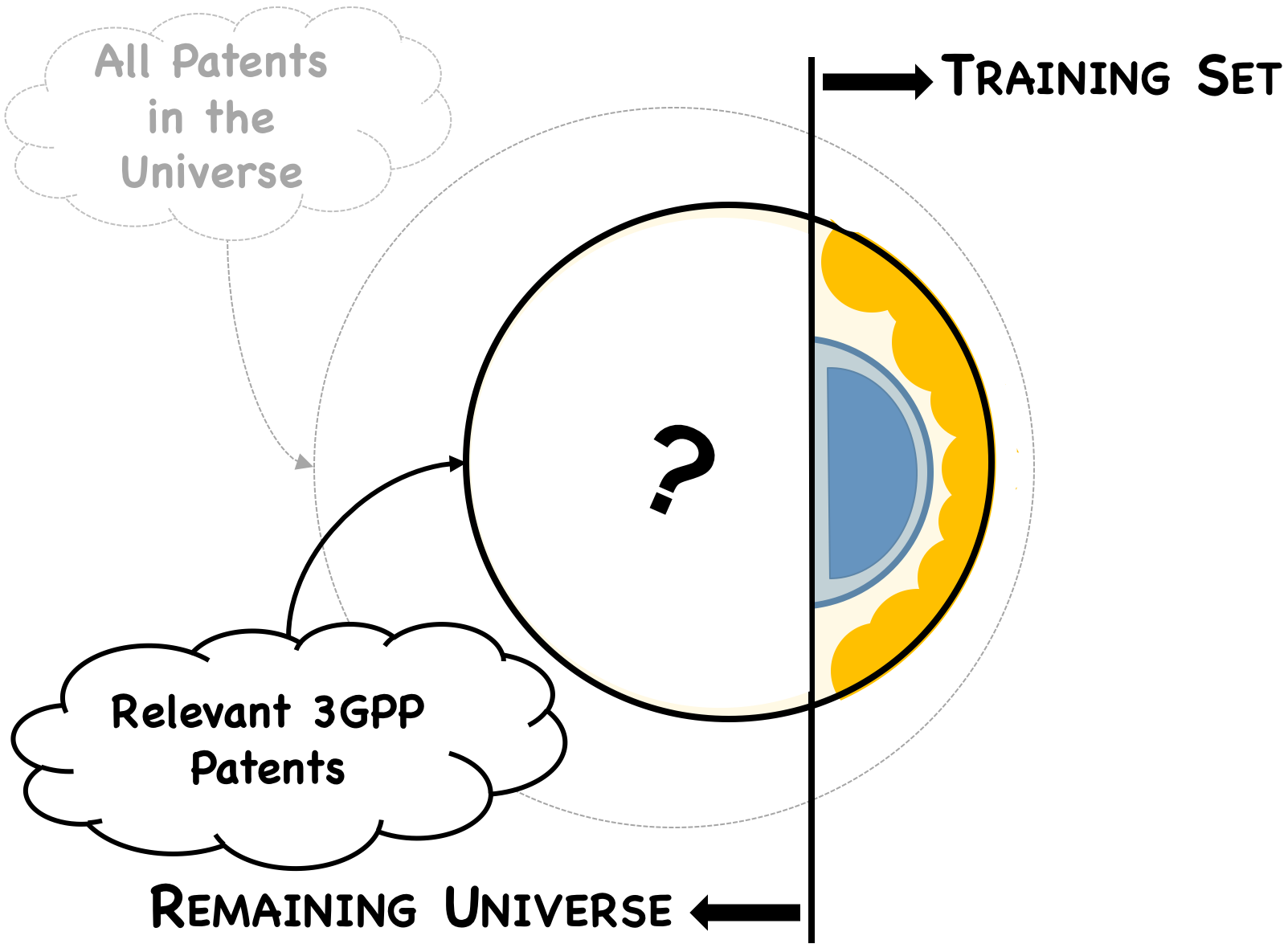
At a minimum, our landscape includes:
- Patents belonging to the "Known Universe" of 3GPP patents. This “Known Universe” includes patents declared at the ETSI as essential to 2G, 3G, LTE, and 5G.
- Patents having at least one inventive CPC subgroup belonging to one of the top-ten CPC subgroups of the "Known Universe."
- Patents that cite to LTE technical proposals.
- Patents that include highly-specific LTE keywords within their title, abstract, description, or backward citations.
After expanding by family, the overall size of our landscape’s universe is on the order of ~2M patents (worldwide), the overwhelming majority of which are either relevant or at least tangential to 3GPP technology.
Similarity Score
Using the assumed set of True Positives and Negatives, we trained a machine learning algorithm to assign a “Similarity” score to each patent.
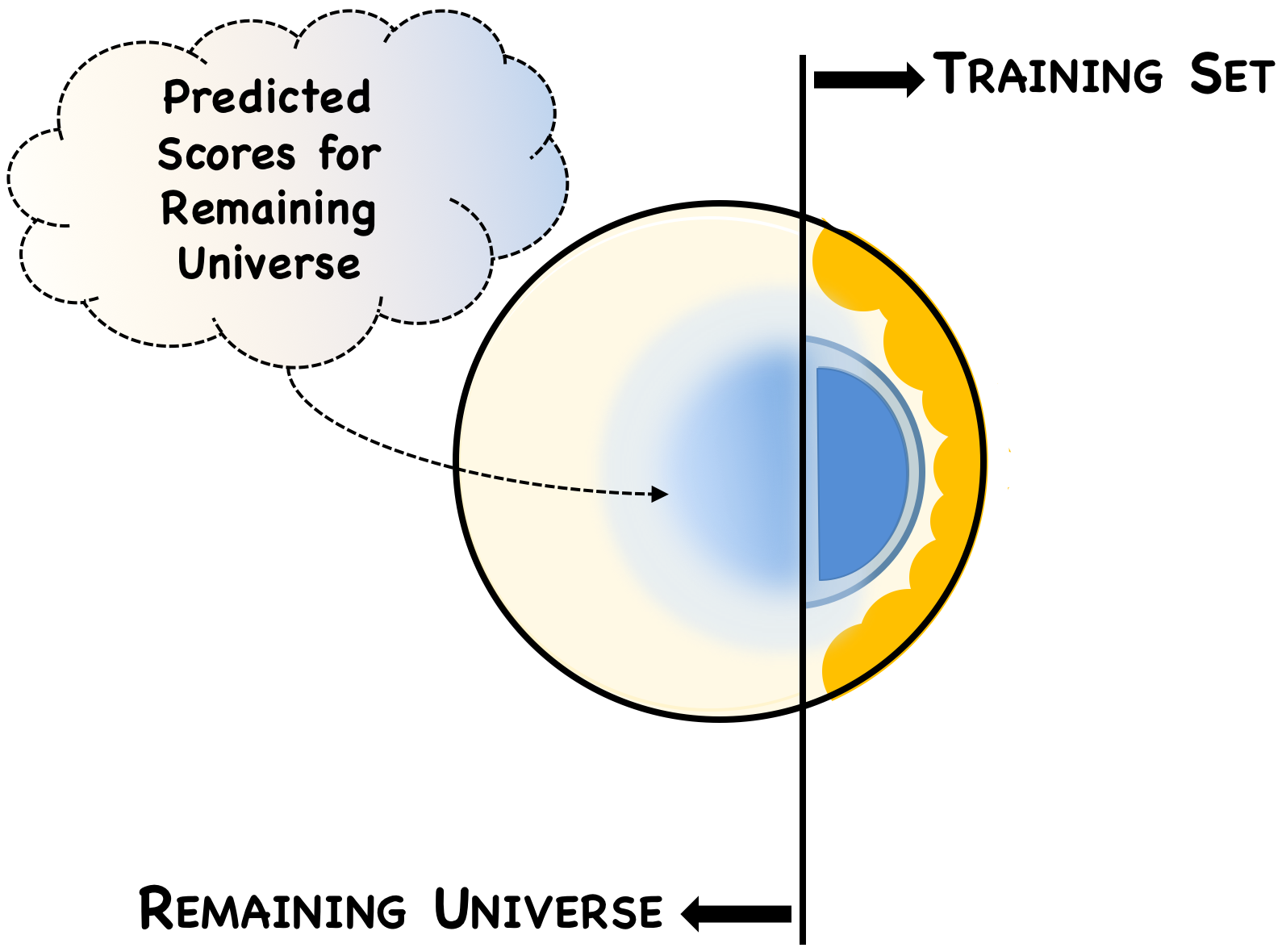
The Similarity Score is a number between 0 and 1 that measures the degree of textual similarity between any given patent and the set of True Positives. The higher the score, the more similar that patent is – in terms of its text-based features – to the training set. Our approach looks at the patent title, abstract, description, claims, and classification codes.
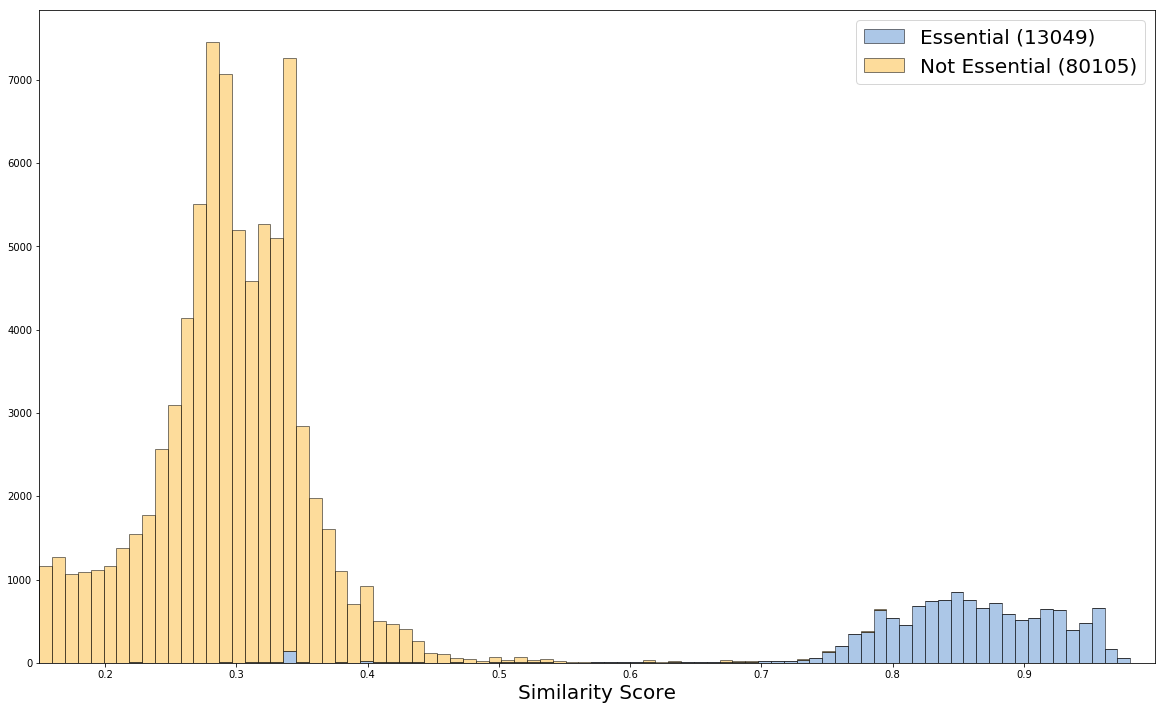
The algorithm is trained until as many True Positives as possible exceed a score of 0.50. In the histogram below, which plots the similarity scores of the training set for similarity >= 0.15, the True Positives are depicted in blue while the True Negatives are depicted in yellow. A standard metric for measuring the performance of a machine learning algorithm is the F1-score, which is the harmonic mean of "precision and recall." In our case, the F1-score is 0.98.
After the training process, the algorithm is applied to the remaining universe of ~2M patents relevant or at least tangential to 3GPP technologies. The histogram below illustrates one of the results of our model. It depicts the distribution LTE patents when the similarity threshold is set to the default baseline of 0.66. This baseline captures roughly ~1500 families, which is also the size of the LTE universe (the "denominator") as determined in the aforementioned TCL v. Ericsson FRAND opinion (see pg. 32 here).
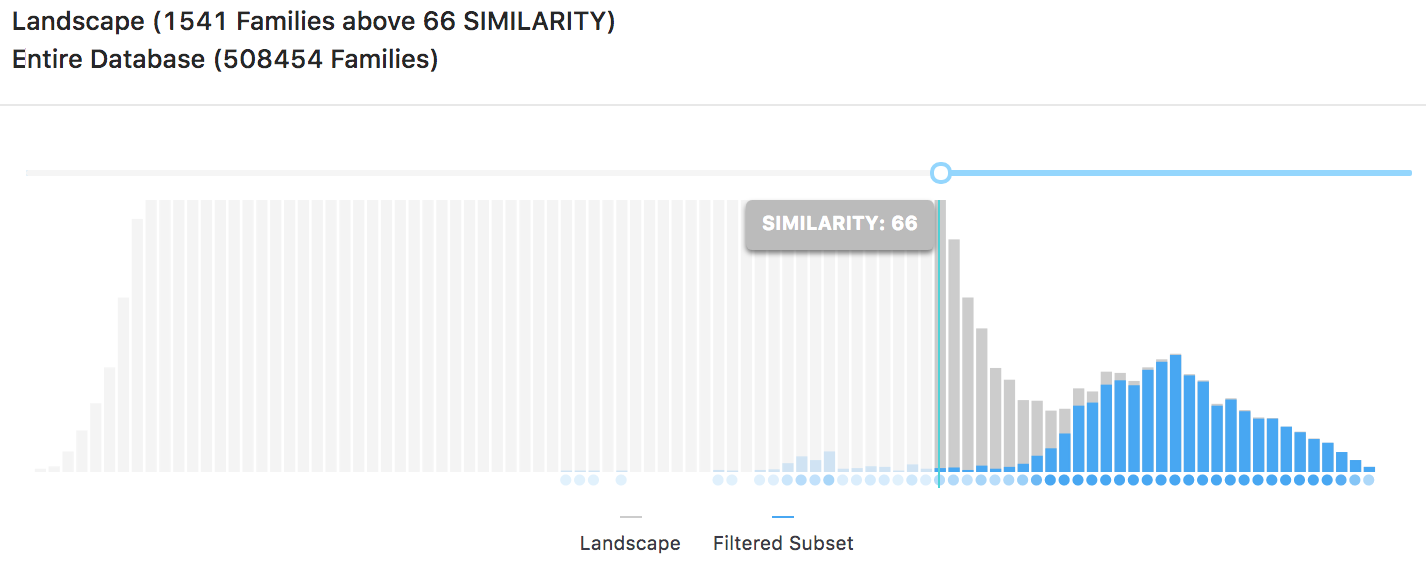
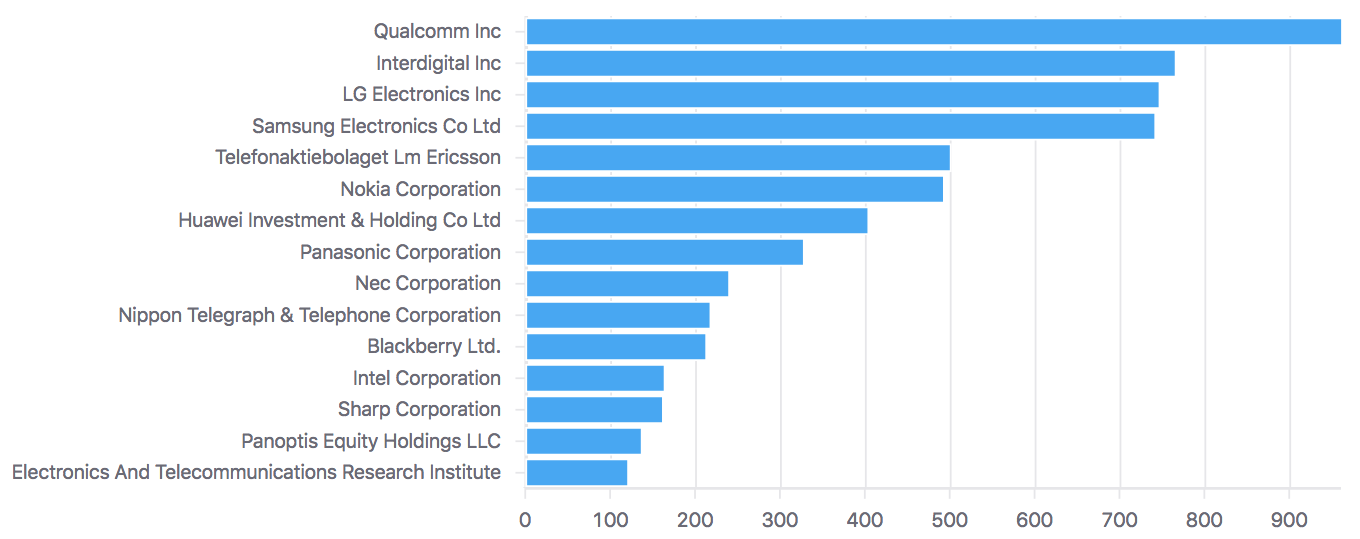
The "filtered subset," shown above in blue, corresponds to the training set's True Positives. The 66 baseline captures more than 95% of the positives. Moreover, these positives make up roughly 1/3 of the ~1500 patent families available in universe at 66. This is consistent with how True Positives were constructed: by taking a representative 1/3 random sample of ETSI-declared LTE patent families and then later verifying those families for essentiality. The figure below shows the allocation of issued patents world-wide for the top LTE patent owners, again at the 66-baseline.
Change Log
- Version 0
- The methodology of this initial version of the LTE landscape is similar to the methodology adopted in our version 1 of the HEVC landscape.
- For the training set, the set of true positives consists of the LTE patents listed as essential by the Via and SISVEL patent pools.
- Version 1
- Our choice of training data in v1 departs from v0. Part of the training set is sourced from a previous litigation. The true negatives also include patents that are not declared to LTE but are declared to other 3GPP standards such as 2G and 3G.
- We introduced Gradient Boost into our ensemble of models in order to improve the landscape's accuracy.
- We have also worked to improve the quality of assignee data points, such has parent company and current/original patent owners. This will be an ongoing process for us.
For more information about Unified's OPAL Reports, or to learn more about Unified's 3GPP Zone, please contact us at info@unifiedpatents.com.
Comments
0 comments
Article is closed for comments.