
OPAL
Objective PAtent Landscape (OPAL)
Video Codec Zone
Patent Population
General Database – 90,000,000 patents from 98 countries
SEP (Self-Declared Standard Essential Patents) Database – 250,000 patents from 69 countries, 35 SSOs (Standard Setting Organizations) and multiple patent pools
Standards
Technical proposals, specification drafts, meeting minutes, attendance lists and working group participation are all collected and indexed by:
- Parsing all available electronic documents of the standard body
- Normalizing company and individual names
- Matching of standard document IDs to contributions
We host documents (such as technical proposals, meeting summaries, test results, etc.) from select standard-setting bodies on our online portal.
Assumptions
Published and independently-verified essentiality lists provide the best training set for creating the initial landscape and subsequent similarity score. Currently there are two entities who provide such lists: MPEG-LA and HEVC Advance. Other published or publicly-available lists of HEVC patents (e.g. ITU-T declarations and Velos Media assignment records) are not independently-verified for essentiality. Thus, we only assume that the patents included in the MPEG-LA and HEVC Advance essentiality lists are, in fact, essential to HEVC (“True Positives”).
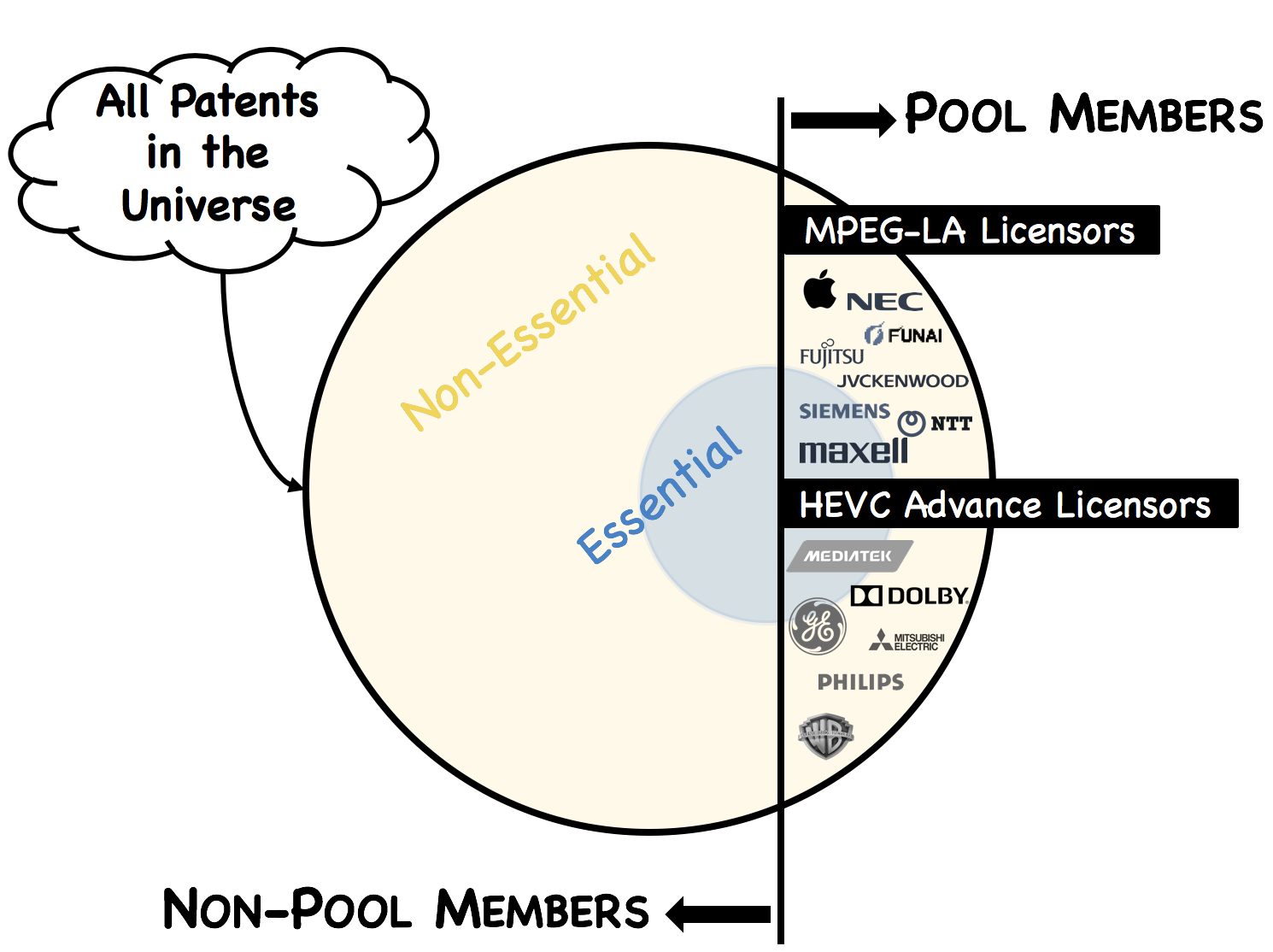
Conversely, we assume that patents that are not included in these essentiality lists which belong to members of MPEG-LA and HEVC Advance (e.g. Canon, JVC Kenwood, MediaTek, Samsung, etc.) are, in general, not HEVC-essential (“True Negatives”). The logic behind this assumption is that either the pool member decided that such patents were not HEVC-essential or, alternatively, the pool itself rejected such patents as not HEVC-essential as part of its independent review process.
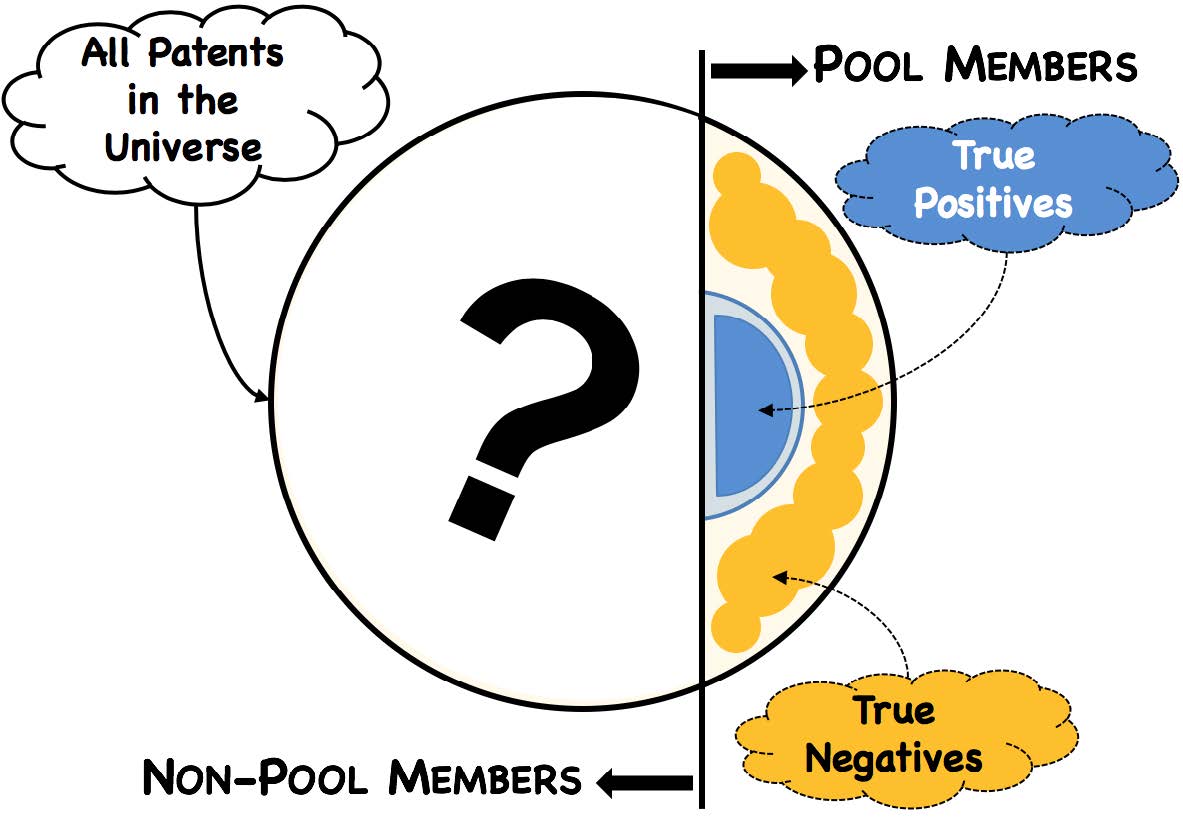
To be conservative, we imposed limitations where this assumption is less plausible or not as strong. For example, 1990-era patents were excluded from this set of True Negatives since – for economic reasons – pool-members may have been less-inclined to submit them for independent review in light of their impending expiration dates.
Landscape Universe
Running a machine learning algorithm on all ~90M patents in the entire patent database is computationally expensive in terms of both costs and time. Thus, using multiple techniques, we narrowed the universe to only those patents that are relevant to (or at least tangential to) video compression technology.
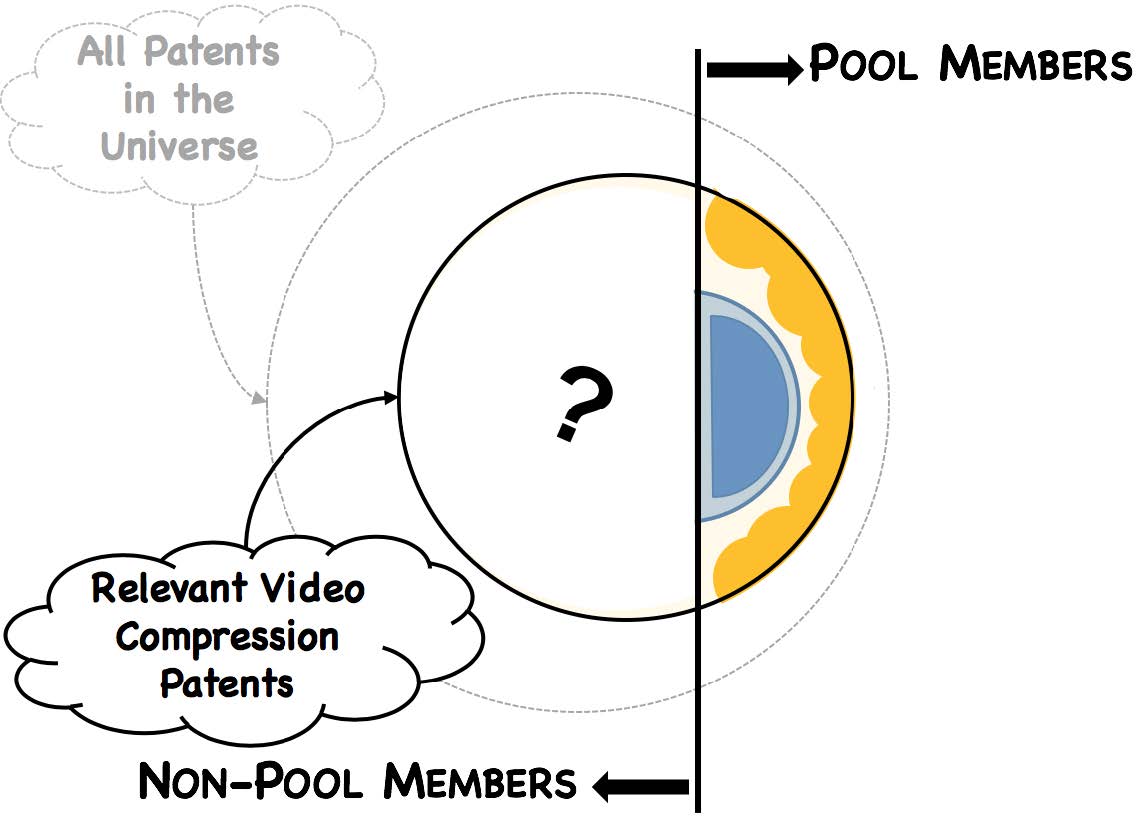
At a minimum, our landscape includes:
- Patents belonging to the "Known Universe" of HEVC and AVC patents. This “Known Universe” includes any HEVC or AVC patent that was included in MPEG-LA or declared at the ITU-T, as well as any HEVC patent that was included in HEVC Advance or assigned to one of the Velos Media entities.
- Patents having at least one inventive CPC subgroup belonging to one of the top-ten CPC subgroups of the "Known Universe."
- Patents that cite to JCT-VC ("Joint Collaborative Team on Video Coding") or JVT ("Joint Video Team") technical proposals.
- Patents that include highly-specific HEVC or AVC keywords (e.g. "High Efficiency Video Coding" or "H.264") within their title, abstract, description, or backward citations.
Moreover, we also applied the techniques described in “Automated Patent Landscaping” by Aaron Abood and Dave Feltenberger to ensure that our universe is not under-inclusive. After expanding by family, the overall size of our landscape’s universe is on the order of ~2M patents (worldwide), the overwhelming majority of which are either relevant or at least tangential to video compression technology.
Similarity Score
Using the assumed set of True Positives and Negatives, we trained a machine learning algorithm to assign a “Similarity” score to each patent.
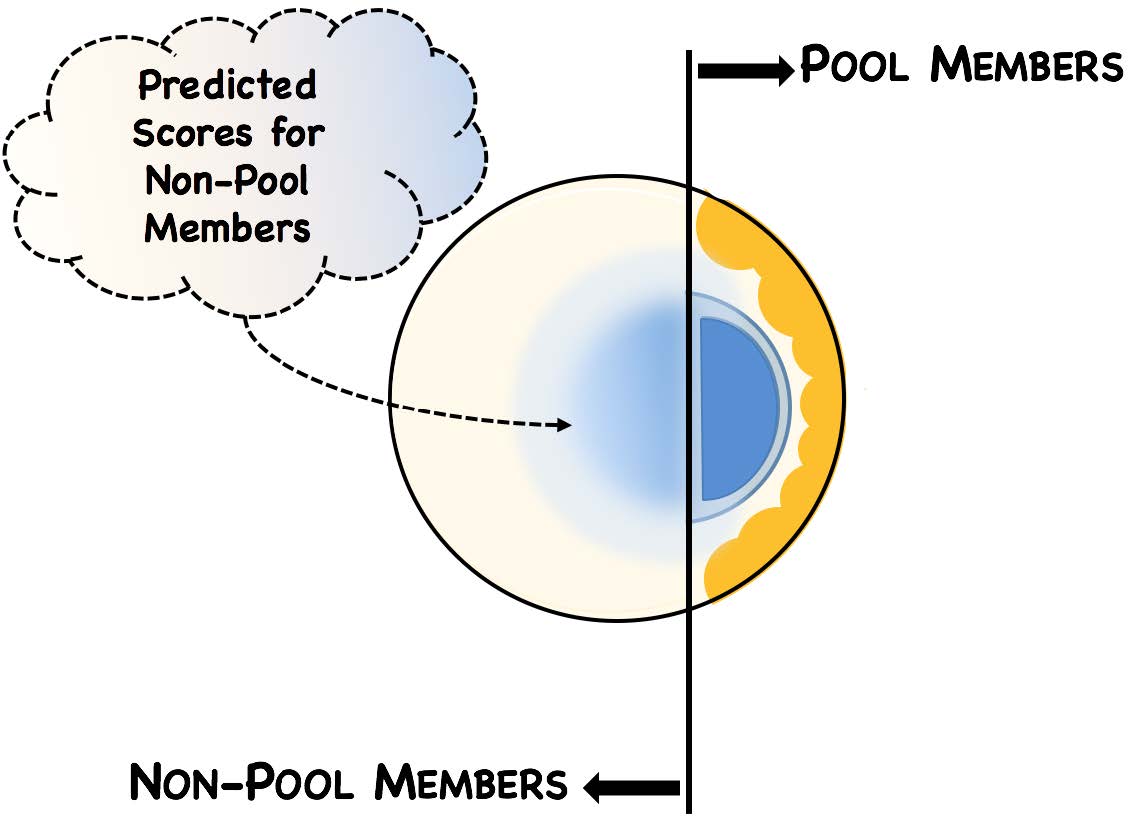
The Similarity Score is a number between 0 and 1 that measures the degree of textual similarity between any given patent and the set of True Positives. The higher the score, the more similar that patent is – in terms of its text-based features – to the independently-verified list of MPEG-LA and HEVC Advance patents. Our approach only looks at the patent title, abstract, description, and claims, ignoring any non-text features such as filing date, classification codes, forward citations, etc.
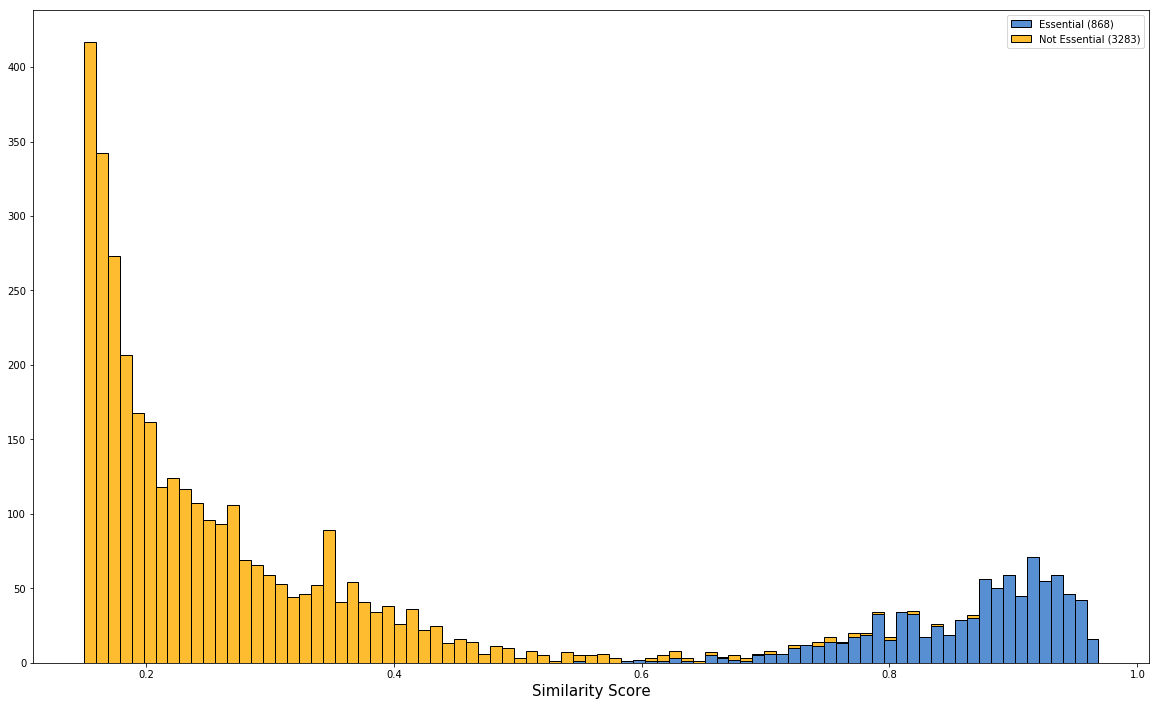
The algorithm is trained until as many True Positives as possible exceed a score of 0.5 ("Baseline"). In the histogram below, which plots the similarity scores of the training set for similarity >= 0.15, the True Positives are depicted in blue while the True Negatives are depicted in yellow. A standard metric for measuring the performance of a machine learning algorithm is the F1-score, which is the harmonic mean of “precision and recall". In our case, the F1-score is 0.96.
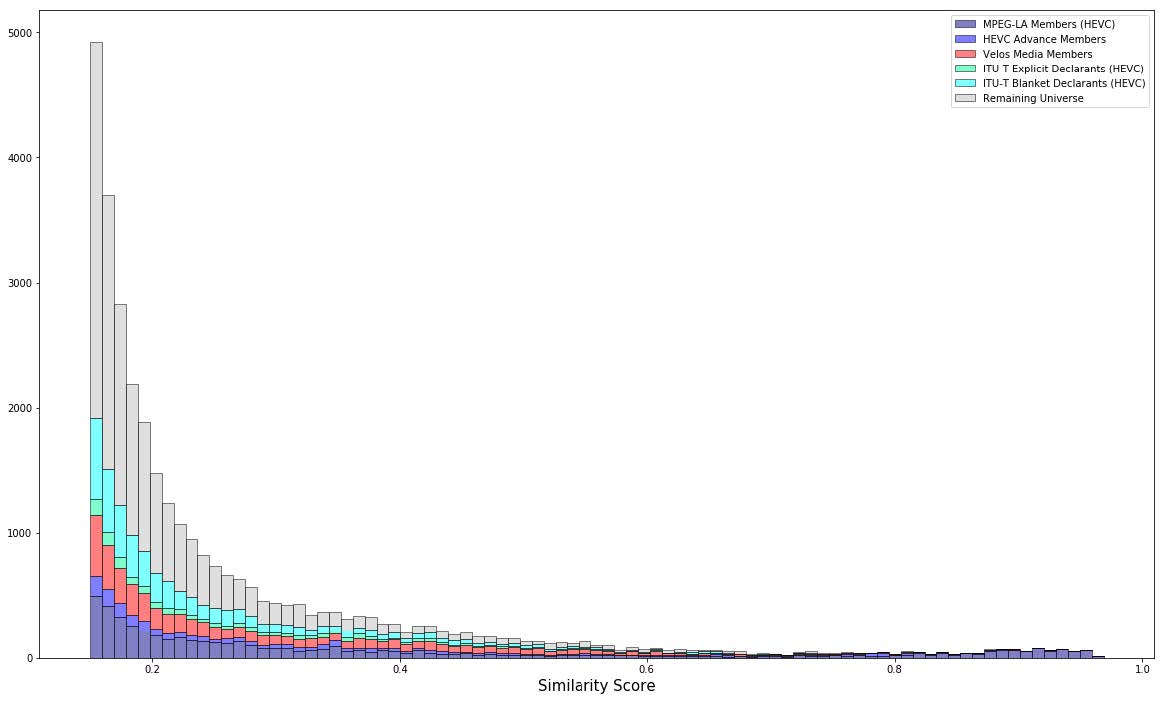
After the training process, the algorithm is applied to the remaining universe of ~2M video compression patents. The histogram below depicts the distribution of similarity scores for different populations of interest (again, for similarity >= 0.15).
Change Log
- Version 0
- The universe of patents, training data, machine learning model, and corresponding similarity scores were provided to Unified Patents by a third party vendor.
- Their methodology can be found here.
- Version 1
- Unified Patents produced this version of the landscape in-house, using raw full-text patent patent data provided by IFI Claims.
- The training data consists of the essentiality lists made available by MPEG-LA and HEVC Advance as of April 2018.
- Version 2
- We updated the positive training labels with the latest (as of January 2019) patent lists from MPEG-LA and HEVC Advance.
- We have also worked to improve the quality of assignee data points, such has parent company and current/original assignee. This will be an ongoing process for us.
- We expanded the size of the negative training labels by relaxing some of the restrictions we imposed on the v1 landscape. This almost tripled the size of the negative labels, so we carefully downsampled the set in order to make it smaller yet still representative.
- We introduced Gradient Boost into our ensemble of models in order to improve performance.
For more information about Unified's OPAL Reports, or to learn more about Unified's Video Codec Zone, please contact us at info@unifiedpatents.com.
Comments
0 comments
Article is closed for comments.